[2/3] Techniques de cryptographie avancée pour la vie privée
Rédigé par Monir Azraoui
-
25 mars 2025Les entretiens avec les experts en cryptographie ont permis d'explorer les techniques cryptographiques protectrices de la vie privée, couramment désignées sous le terme de « PETs » (privacy-enhancing technologies). Bien que ce domaine ait historiquement été un sujet d'intérêt dans le milieu académique depuis plusieurs décennies, il suscite désormais un certain intérêt au-delà de la sphère de la recherche, portant avec lui de grandes promesses. Dans cet article, nous présentons une synthèse des idées partagées lors de ces entretiens avec O. Blazy, S. Canard, M. Önen, P. Pailler et les experts et expertes de l’ANSSI.

Sommaire du dossier
- Article introductif : Des experts nous donnent les clés pour décrypter la cryptographie d'aujourd'hui et de demain
- Article 1 : La cryptographie post-quantique
- Article 2 : Les techniques de cryptographie avancée pour la vie privée
- Article 3 : Les applications pratiques de la cryptographie avancée
Les opérations sur des données chiffrées
Le chiffrement est la principale technique pour assurer la confidentialité des données. Cependant, la nécessité de traiter ces données tout en préservant leur confidentialité pose un défi majeur. Tous les experts auditionnés ont évoqué les perspectives émergentes et les enjeux liés à l'opération sur des données chiffrées.
Le chiffrement (totalement) homomorphe (FHE)
Le chiffrement homomorphe permet d'effectuer des opérations mathématiques sur des données chiffrées sans connaître les données en clair sous-jacentes. Concrètement, cela signifie que des calculs peuvent être réalisés directement sur les données chiffrées, produisant un résultat chiffré qui, une fois déchiffré, correspond au résultat du calcul comme s’il avait été effectué sur les données en clair.

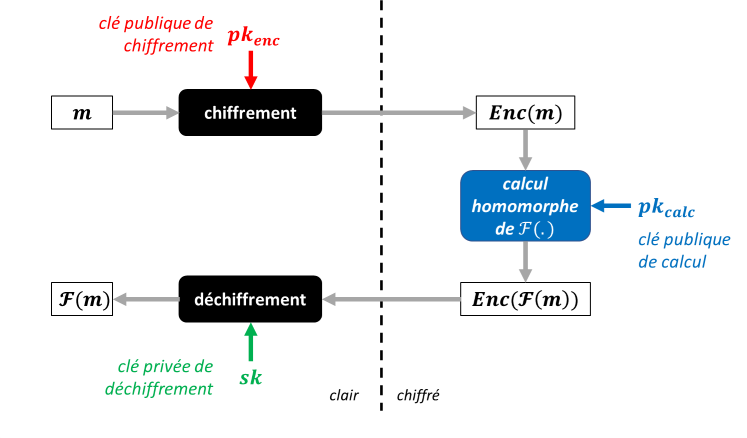
Schéma descriptif du chiffrement homomorphe
Plus précisément, il existe plusieurs classes de chiffrement homomorphe, selon la complexité des opérations que l’on peut réaliser sur le chiffré :
- Le chiffrement « partiellement homomorphe » ne permet ainsi de réaliser qu’un seul type d’opération, l’addition ou la multiplication. Bien que d’un usage moins général que le chiffrement presque ou totalement homomorphe (voir ci-dessous), il a un grand intérêt du fait de sa plus grande efficacité. Parmi les exemples classiques, on peut citer la recherche confidentielle d’information (PIR, private information retrieval), qui s’apparente à une recherche en ligne sans révéler au moteur de recherche les termes recherchés, qu’il est possible de réaliser avec un chiffrement partiellement homomorphe.
- Le chiffrement « presque homomorphe » (somewhat homomorphic encryption) permet d’effectuer un faible nombre d’opérations avant que le chiffré en résultant ne devienne impossible à déchiffrer.
- Le chiffrement « totalement homomorphe » (fully homomorphic encryption ; FHE) permet de réaliser des opérations arbitraires sur les chiffrés et dispose donc en théorie des applications les plus nombreuses.
Imaginé dès la fin des années 1970, une première réalisation théorique du FHE n’est apparue qu’en 2009 grâce aux travaux de Craig Gentry[1]. Le mécanisme proposé par Gentry repose sur les réseaux euclidiens structurés mais est peu efficace en pratique. Son utilisation a été limitée par une trop grande complexité et des coûts de performance importants par rapport aux calculs en clair. Depuis, avec un regain d’intérêt de l’industrie, le FHE a fait des progrès significatifs en termes de praticité, grâce à des avancées continues dans les domaines de l'algorithmique, de la performance matérielle et de l'optimisation logicielle.
Les perspectives du chiffrement homomorphe
L’un des experts a dressé un panorama des solutions proposées par les acteurs de cet écosystème :
- Au niveau « matériel » : les calculs en FHE sur les données chiffrées requièrent un nombre d’opérations beaucoup plus grand que ceux sur les données non chiffrées. Pour permettre des calculs plus rapides, une accélération matérielle peut être nécessaire. Des sociétés comme Intel, Optalysys ou Galois Inc sont en train de développer des processeurs conçus spécifiquement pour effectuer des opérations mathématiques demandant d’importantes ressources de calculs.
- Au niveau « logiciel » : la mise à disposition de bibliothèques logicielles, c’est-à-dire de codes informatiques fournissant des fonctionnalités spécifiques pour le FHE, à destination des développeurs, est un atout majeur pour la démocratisation du chiffrement homomorphe. Des acteurs comme IBM et Microsoft proposent respectivement les bibliothèques HELib et SEAL. D’autres sociétés plus petites sont aussi sur ce secteur (Duality Technologies, Inpher, Cosmian, etc.).
- Au niveau « compilateur » : les compilateurs FHE sont des outils logiciels qui simplifient la programmation de fonctions pouvant être exécutées dans le domaine chiffré. Ils permettent de traduire des programmes informatiques en instructions compatibles avec le FHE permettant d’adapter facilement des programmes. Google et la startup française Zama proposent de tels compilateurs. Le CEA propose aussi son compilateur Cingulata du CEA-LIST en open source.
La plupart des experts auditionnés ont reconnu que les outils FHE disponibles aujourd’hui permettent de s’emparer de la technologie, même pour une personne non experte en cryptographie. En termes d’efficacité, le FHE progresse vers une plus grande praticabilité mais demande encore d’importants investissements technologiques pour être utilisable dans l’industrie.
D’autres perspectives de recherche autour du FHE ont également été évoquées au cours des échanges :
- La première piste de recherche concerne les situations impliquant des sources de données multiples souhaitant opérer sur leurs données mutualisées. Le FHE classique ne permet pas ce type de configuration et dans ce cas, le FHE multipartite ou le FHE à clés multiples sont à prioriser.
- La seconde piste de recherche se focalise sur la vérification de l’exactitude et de l’intégrité des calculs effectués en FHE (« verifiable FHE »). Elle se place dans le cas d’un serveur cloud qui effectue les calculs qu’un client lui délègue et qui pourrait compromettre l’exactitude du calcul sur les données chiffrées. Les solutions de verifiable FHE permettraient au client de vérifier l'intégrité des calculs effectués sur les données chiffrées sur la base d’une preuve générée par le cloud. L’enjeu de ces solutions réside dans le fait que la vérification de la preuve doit être plus efficace que d’effectuer le calcul par le client lui-même.
Le chiffrement fonctionnel
Certains experts ont mentionné le chiffrement fonctionnel comme outil complémentaire pour effectuer des opérations sur les données chiffrées. Il consiste à chiffrer les données de telle manière qu'il soit possible de les déchiffrer de manière sélective, en fonction des opérations que l'utilisateur est habilité à réaliser. Le chiffrement fonctionnel permet donc de contrôler l'accès aux données selon les fonctions spécifiques que chaque utilisateur est autorisé à effectuer. Pour chaque fonction, une clé de déchiffrement spécifique est donc générée.
En FHE, n’importe quel calcul est en théorie possible par le détenteur des données chiffré, mais le résultat est chiffré et doit être communiqué au détenteur de la clé de déchiffrement pour pouvoir accéder à son contenu en clair. Avec le chiffrement fonctionnel, le résultat du calcul est directement accessible en clair après le calcul réalisé, mais le détenteur des données ne peut effectuer que des traitements autorisés par son propriétaire. En fonction des scénarios d'utilisation spécifiques, l'une ou l'autre de ces techniques peut ainsi se révéler plus pertinente.
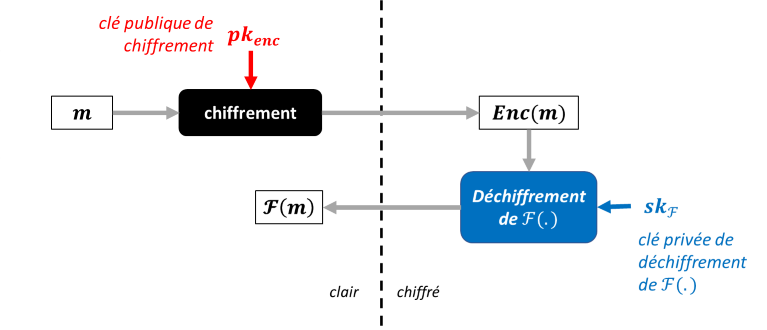
Schéma descriptif du chiffrement fonctionnel
Aujourd’hui, le chiffrement fonctionnel n’en est encore qu’à ses balbutiements. En termes d’efficacité, la recherche dans ce domaine a principalement porté sur des opérations spécifiques, comme le produit scalaire, pour lesquelles des solutions ont été trouvées pour améliorer la performance et la praticabilité. Cependant, lorsqu'il s'agit d'appliquer le chiffrement fonctionnel à des fonctions plus générales et complexes, les performances restent prohibitives pour un déploiement à grande échelle.
Il s’agit donc d’un domaine de recherche actif, afin de rendre le chiffrement fonctionnel plus efficace et pratique.
Le calcul multipartite sécurisé (MPC)
Pour opérer des calculs sur les données chiffrées, le MPC a également été évoqué au cours des entretiens avec les experts. Cette branche de la cryptographie, apparue dans les années 80, a été largement explorée depuis. Le MPC n'a cessé d'évoluer au fil des ans, devenant de plus en plus pratique et applicable dans divers cas d’usage.
L’un des premiers protocoles de MPC, le « circuit brouillé » (garbled circuits), a été proposé par Andrew Yao en 1982. Dans son étude, Yao introduit le fameux « problème des millionnaires » : deux millionnaires souhaitent déterminer lequel d’entre eux est le plus riche, sans divulguer à l’autre la valeur exacte de sa fortune. Une solution naïve mais complexe à mettre en œuvre serait de recourir à une tierce partie de confiance : chacun des millionnaires communique la valeur de sa fortune à ce tiers de confiance qui pourra déterminer le plus riche sans rien révéler d’autre. Les techniques de MPC tentent de reproduire ce scénario sans recourir au tiers de confiance, mais avec les mêmes garanties de confidentialité et de fiabilité du résultat.
Dans un protocole de MPC, un ensemble de parties, qui ne se font pas confiance, collaborent pour calculer conjointement une fonction sur leurs données, sans jamais révéler aux autres participants quoi que ce soit des données initiales, à l'exception de ce qui est impliqué par le résultat final de la fonction. Ce processus repose sur des techniques cryptographiques avancées (partage de secret sécurisé – secret sharing ; transfert inconscient – oblivious transfer ; chiffrement homomorphe, etc.) et sur la communication entre les participants.
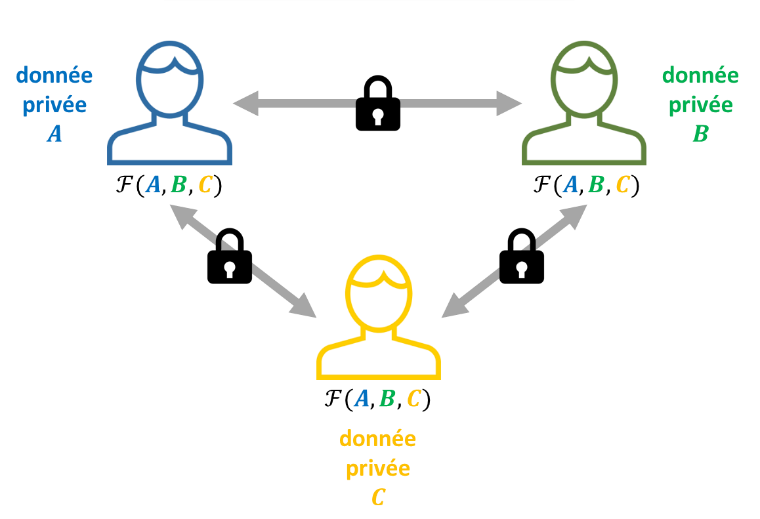
 Schéma descriptif du calcul multipartite sécurisé d’une fonction F
Schéma descriptif du calcul multipartite sécurisé d’une fonction F
Il existe deux principaux types de protocoles de MPC :
- Les protocoles génériques qui permettent de calculer une fonction arbitraire sur les données des parties. Ils peuvent être flexibles et adaptés à plusieurs applications, mais peuvent être complexes et couteux à mettre en œuvre ;
- Les protocoles spécialisés, ou ad-hoc, qui sont conçus pour des fonctions spécifiques choisies à l’avance. Ces protocoles sont optimisés pour ces tâches particulières et sont souvent plus efficaces en termes de temps de calcul et de ressources nécessaires. Ils ont suffisamment été étudiés pour être utilisables aujourd’hui. C’est en particulier le cas pour les protocoles permettant le calcul d’intersection d’ensembles privés (private set intersection – voir plus bas) dont les temps de calcul ont été réduits considérablement par rapport aux premières ébauches de protocoles.
Certains experts auditionnés ont mentionné les outils pour le développement de solutions à base de MPC (à savoir SCALE-MAMBA et MP-SPDZ). Ces outils open-source peuvent être utilisés pour compiler une fonction générale en un protocole MPC sécurisé.
Depuis quelques années, les progrès en matière de MPC ont permis d’envisager la mise en place de systèmes fondés sur ce paradigme. En outre, les applications à base de MPC sont souvent plus mûres que les applications reposant uniquement sur le chiffrement homomorphe. Cela s'explique par le fait que le chiffrement homomorphe reste plus couteux que le MPC, notamment pour des opérations à grande échelle. Depuis plusieurs années, il existe des applications concrètes du MPC :
- Au Danemark, en 2008, une vente aux enchères de betteraves sucrières a été sécurisée via du MPC ;
- À Boston, depuis 2016, des études sur les inégalités salariales entre les hommes et les femmes commandées par le Boston Women's Workforce Council sont réalisées à l’aide de techniques de MPC.
Focus sur le PSI
Le calcul d'intersection d'ensembles privés (Private Set Intersection, PSI) est une forme de MPC qui permet à plusieurs parties de trouver des éléments communs dans leurs ensembles de données sans révéler le contenu de leurs ensembles de données respectifs. Le PSI ne révèle que les éléments partagés (l’intersection) dans les différents ensembles de données. Parmi tous les protocoles de MPC existants, le PSI est sans doute celui qui a connu plus d’applications concrètes (ou projets d’utilisation) : les outils de surveillance des mots de passe d’Apple, de Google ou encore le projet d’Apple concernant la détection de contenus pédopornographiques (CSAM).
Les preuves de connaissance à divulgation nulle de connaissance
Certains experts interrogés ont identifié les preuves de connaissance à divulgation nulle de connaissance (Zero Knowledge Proofs ou ZKP) comme des mécanismes cryptographiques pouvant être immédiatement déployés dans divers cas d'utilisation réels. Des preuves de concept existent déjà, notamment dans le cadre de la vérification d’âge respectueuse de la vie privée. Les ZKP sont également promus par un certain nombre d’experts pour la mise en œuvre des futurs portefeuilles d'identité numérique européens prévus dans le cadre du règlement de l'Union européenne sur l'identification électronique et les services de confiance pour les transactions électroniques dans le marché intérieur (règlement eIDAS 2).
Ces preuves, introduites dès les années 80, permettent de prouver qu’une condition (ou assertion) est vraie, sans en révéler l’information sous-jacente, afin d’en assurer la confidentialité. Elles peuvent être utiles dans de nombreux scénarios : prouver la majorité d’une personne sans dévoiler son identité, prouver qu’on dispose d’une certaine somme d’argent sans révéler le solde de son compte en banque, etc.
Les ZKP présentent encore des défis importants en termes d'implémentation. En effet, leur conception exige une expertise en cryptographie avancée et leur traduction en application réelle requiert une compréhension approfondie des concepts sous-jacents.
Par ailleurs, la mise en œuvre pratique des ZKP peut parfois nécessiter dans certains cas des ressources importantes en termes de puissance de calcul. Pour des applications telles que la vérification d'âge, où un serveur n'a pas besoin de vérifier un grand nombre de preuves simultanément, cela peut ne pas poser de problème majeur. En revanche, pour des applications à grande échelle, comme l'utilisation des ZKP dans la blockchain, les temps de réponse peuvent être cruciaux. Trouver le meilleur compromis entre confidentialité et performance reste un défi majeur : certains protocoles peuvent sacrifier un peu de confidentialité pour obtenir de meilleures performances ou vice versa.
De plus, un autre défi réside dans le fait que certains systèmes de ZKP exigent une phase de configuration de confiance (« trusted setup phase ») pour générer les paramètres initiaux nécessaires pour le déroulement du protocole de preuve. Cette phase pourrait nécessiter des hypothèses de confiance trop exigeantes dans le monde réel.
Toutefois, les ZKP sont toujours en évolution et gagnent en maturité. La recherche dans ce domaine se concentre notamment sur l’amélioration de l’efficacité des calculs, la réduction des besoins en ressources et la standardisation pour une adoption généralisée. Ces avancées peuvent être même catalysées du fait de la mention explicite des ZKP dans le considérant 14 du règlement eIDAS 2.
Dans un avenir proche, les experts auditionnés anticipent une intégration plus générale des ZKP à mesure que ces systèmes vont gagner en performances. Par ailleurs, des solutions de ZKP résistantes aux attaques quantiques existent et sont des sujets de recherche en cours. D’autres pistes de recherches sur les ZKP tendent à les combiner ou à les fabriquer à partir d’autres briques cryptographiques. Ainsi, le « MPC-in-the-head », un paradigme de construction d'un système de ZKP à partir d'un protocole de calcul multipartite (MPC), a fait l’objet de plusieurs publications scientifiques. D’autres travaux en cours combinent les ZKP avec le FHE pour la confidentialité et la vérifiabilité des calculs de données chiffrées, comme discuté plus haut.
Les signatures de groupe
Cette technologie a été introduite dans les années 1990 par Chaum et van Heyst. Elle désigne un type de signature électronique pour un groupe de personnes. Au groupe est associée une unique clé publique de vérification de la signature. Chaque membre du groupe possède sa propre clé privée de signature avec laquelle il peut générer des signatures pouvant être vérifiées avec la clé publique du groupe. Ce type de signature permet à un membre du groupe de prouver son appartenance au groupe sans avoir à révéler son identité (c’est-à-dire qu’il est en pratique difficile de déterminer quel membre du groupe a généré la signature). Chaque membre du groupe peut signer des messages au nom du groupe et, comme n’importe quelle signature électronique, n’importe qui peut vérifier la signature. Il est possible de donner à une autorité de confiance le pouvoir de révéler l’identité du signataire.
Les signatures de groupe sont un mécanisme cryptographique éprouvé. Certaines formes de signatures de groupe sont déjà standardisées à l’ISO (l’organisation internationale de normalisation) dans la norme ISO/IEC 20008. Des signatures de groupe sont utilisées dans le monde industriel, notamment dans les cryptoprocesseurs TPM (Trusted Platform Module), sous la forme de Direct Anonymous Attestations, une primitive cryptographique permettant d’authentifier à distance le TPM tout en préservant l’identité de l’utilisateur de la plateforme contenant le module. Une approche similaire est utilisée dans les processeurs Intel (sous la forme d’EPID, Enhanced Privacy ID).
Néanmoins, l’un des experts interrogés regrette que les signatures de groupe ne soient cantonnées qu’à la recherche et au développement, malgré l’existence d’implémentations efficaces et de standards établis. Un exemple d’application évoqué, qui fonctionnerait efficacement en pratique, serait l’utilisation des signatures de groupe pour contrôler l’accès à l’entrée d’un immeuble ou encore la vérification d’âge respectueuse de la vie privée. À ce sujet, le LINC a publié un démonstrateur du mécanisme de vérification de l’âge basé sur les signatures de groupe.
Conclusion
À l’heure où la protection de la vie privée est une préoccupation majeure, les entretiens avec des experts en cryptographie ont permis de tirer plusieurs enseignements.
L'émergence des privacy-enhancing technologies (PETs) comme le chiffrement homomorphe (FHE) et les preuves de connaissance à divulgation nulle de connaissance (ZKP) ou les signatures de groupe offre des solutions innovantes pour répondre à ces préoccupations. Malgré les avancées significatives dans ces domaines, des défis persistent, notamment en termes de performance et de praticabilité. Toutefois, avec l’intérêt croissant de l'industrie et les efforts continus de la recherche, l'adoption généralisée de ces technologies semble de plus en plus réaliste.
Bien que le RGPD ne mentionne pas explicitement ces technologies, son article 25 sur la « protection des données dès la conception et par défaut » souligne leur importance qu’elles pourraient avoir pour respecter cette obligation. La CNIL pourrait promouvoir et encourager leur utilisation dans le cadre de la mise en œuvre du règlement afin de renforcer la protection des données personnelles.
[1] Gentry, C. (2009, Mai). Fully homomorphic encryption using ideal lattices. In Proceedings of the forty-first annual ACM symposium on Theory of computing (pp. 169-178).
Illustration : pexels